
Photo by Stephen Phillips - Hostreviews.co.uk on Unsplash
Exploratory Data Analysis Ultimate Guide
EDA Essentials: A Practical Guide to Extracting Value from Your Data


The phrase "Data is the new gold", emphasizes the increasing value of data in today's world. When properly analyzed, data can uncover valuable insights that inform critical decisions and shape the future. In order to extract insights from data, one must first understand it. This is where Exploratory Data Analysis (EDA) comes in.
1. What is Exploratory Data Analysis?
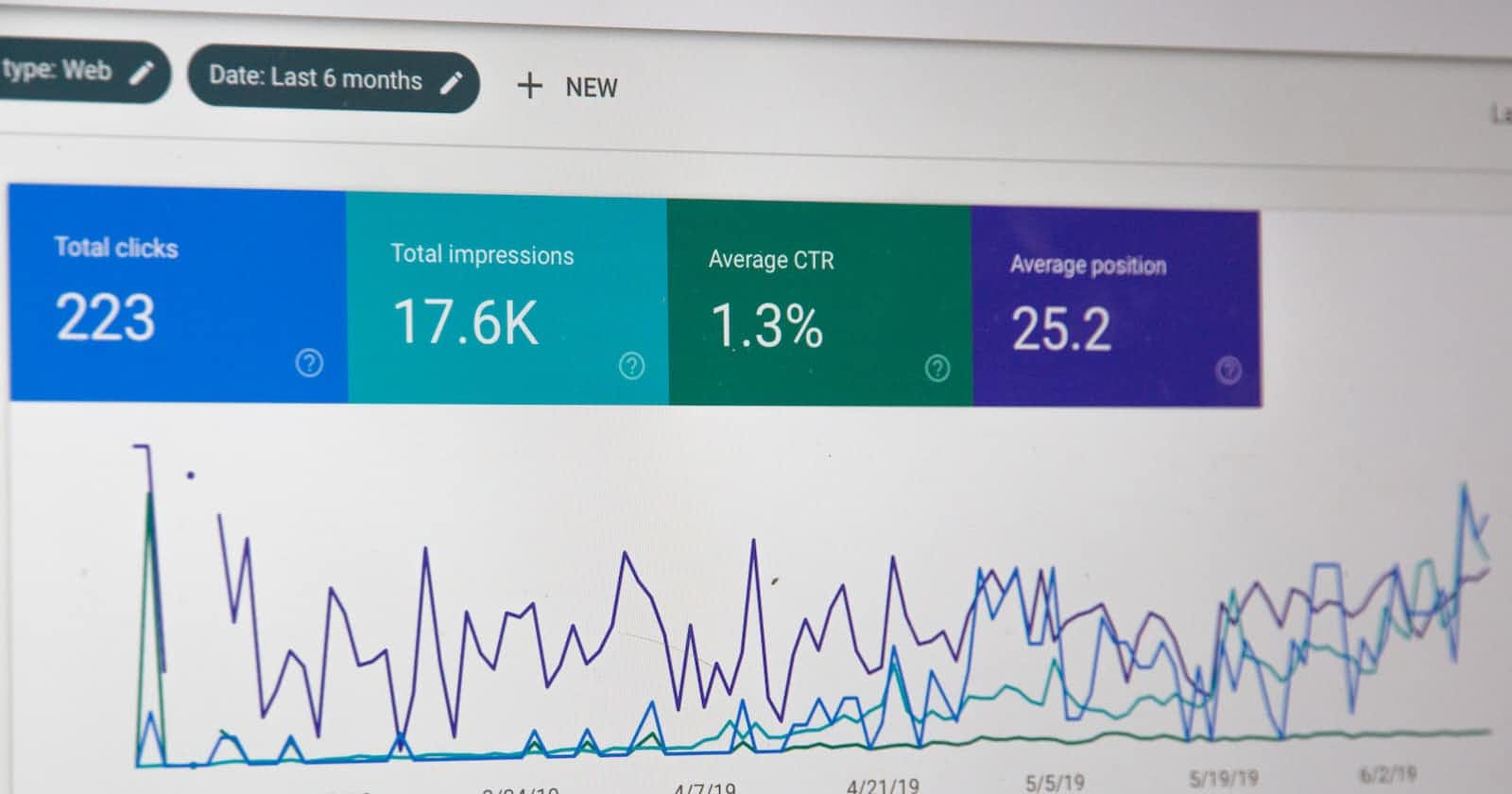
Exploratory data analysis is one of the first steps in the data analytics process. It entails the application of various techniques in the analysis of the dataset to understand the data.
Understanding the dataset simply means getting to know the data and its characteristics, which can help in identifying potential issues, patterns, and relationships within the data.
2. What is the objective of Exploratory Data Analysis?
There are two main objectives of EDA:
EDA assists in identifying faulty points in the data. Once the faulty points have been identified, they can be easily removed, resulting in data cleaning.
It also helps in understanding the relationship between the variables. This gives a wider perspective on the data which helps in building models by utilizing the relationship between various features(variables).
3.Types of Exploratory Data Analysis
There are two main types of exploratory data analysis which are Univariate EDA and Multivariate EDA.
Univariate EDA
Uni means one and variate means variable, so in Univariate Analysis, there is only one dependable variable. The goal of univariate analysis is to simply describe the data and find patterns with the data. Univariate EDA techniques include:
Univariate non-graphical EDA techniques:
Central Tendency (mean, mode and median)
Dispersion (range, variance)
Quartiles (interquartile range)
Standard deviation.
Univariate graphical EDA techniques:
These are graphical methods that provide a visualization of the data. Common types of univariate graphics include:
Histograms are graph plots in which each bar represents the frequency distribution of numerical data.
Box plots, which graphically depict the five-number summary of minimum, first quartile, median, third quartile and maximum.
Multivariate EDA
This is a method of analyzing data involving more than two variables. The goal is to understand patterns, correlations and interactions between variables. Multivariate techniques include:
Multivariate non-graphical EDA techniques:
These techniques generally show the relationship between two or more variables of the data through cross-tabulation or statistics.
Multivariate graphical EDA techniques:
These are graphical methods that display the relationships between two or more sets of data. Common types of multivariate graphics include:
Scatter plot, is used to plot two quantitative variables on a horizontal (x-axis) and vertical(y-axis) to display the relationship between the continuous variables.
Multivariate chart is a graphical representation of the relationships between factors and responses.
Run chart a line graph drawn over time. It visually illustrates the data values in a time sequence.
Bubble charts are scatter plots that display multiple circles (bubbles) in a two-dimensional plot.
Heatmap is a graphical representation of data in the form of a map or diagram in which data values are represented as colors.
4. Exploratory Data Analysis Tools
Python
Python is used for different tasks in EDA, such as finding missing values in data collection, data description, handling outliers, obtaining insights through charts etc.
R
R programming language is a regularly used option to make statistical observations and analyze data, i.e., perform detailed EDA by data scientists and statisticians.
MATLAB
It is common among engineers and domain experts due to its strong mathematical calculation ability.
5. Steps involved in Exploratory Data Analysis
There are three main steps involved in exploratory data analysis. They can be simplified as data collection, data cleaning and analysis of the relationship between the variables.
1. Data Collection
It is the first step in EDA, it involves gathering relevant data from various sources. Some reliable sites for data collection are Kaggle, GitHub, UCI Machine Learning Repository etc.
The data depicted in the example represents the 120 years of Olympic History dataset that is available on Kaggle.
While at the IDE of choice, start by importing the necessary libraries.

Then, load the dataset into DataFrames:

Display the content of the datasets:

Regions dataset:

Check the shape of the DataFrames:

This DataFrame shape is (271116, 15) which means that it has 271116 observations (rows) and 15 features (columns). Checking the region's DataFrame shape:

The DataFrame shape is (230, 3) which implies that it has 230 rows and 3 columns. Next, Merge the two DataFrames:

Check the shape of the Olympics DataFrame:

Display the content of the Olympics DataFrame:

Check the concise summary of the DataFrame using the info() function.

Check the descriptive analysis of the DataFrame using the describe() function. It provides descriptive information about the dataset.

2. Data Cleaning
This is a critical step in EDA that involves identifying and correcting errors and inconsistencies in the data to ensure its accuracy and integrity.
1. Handling the missing values.
This is a crucial step in data analysis. Missing values can be handled in various ways:
Removing missing values - this is simply removing any rows or columns that contain missing values. This is only appropriate if the amount of missing data is small relative to the size of the dataset and removing the missing data does not significantly affect the analysis.
Imputing missing values - this is imputing the missing value with an estimated value. The simplest approach is to impute the missing values with the mean, median, or mode of the non-missing values. More advanced imputation techniques involve using machine learning algorithms to predict the missing values based on other features in the dataset.
Ignoring missing values- in some cases, it may be appropriate to ignore missing values if they do not significantly affect the analysis.
Handling missing values in the Olympics dataset:
First check for missing values:

Then, the percentage of missing values:

The results above provide insights on how to handle the missing values in the Olympics dataset.
The Notes column has 98% of the data missing and can therefore be dropped.

The Height and Weight missing values can be imputed by the mean.

The Age column has 3% of the data missing, while the Region has 0.3%, this value is relatively small and thus any modification to the column can be ignored. The missing values in the Medal column are ignored since Nan indicates that no medals were won.
2. Handling duplicate values.
This involves identifying and removing or modifying duplicates. Here are some common approaches to handling duplicate values:
Identifying and removing exact duplicates- Exact duplicates are rows that have identical values in all columns.
Identifying and removing partial duplicates- Partial duplicates are rows that have the same values in some columns but differ in others.
Here's a code example of how to handle the duplicates mentioned above:

The Olympics dataset does not require this check because duplicates are inevitable given the nature of the data.
3. Analyzing the relationship between the variables.
####Univariate non-graphical EDA Top 10 participating countries

Univariate graphical EDA
Bar plot for Top 10 participating countries

code:

Age distribution of the athletes

code:

Interpretation: Most participants were aged between 23-26 years.
Height distribution of the athletes

Code:

Interpretation: The height of the athletes ranges between 150cm to 178cm. Most of the participants had a height of 175cm
Multivariate non-graphical EDA
Number of athletes in respect to their gender

Top 15 Countries and number of Gold Medals Won in the 2016 Olympics

Multivariate graphical EDA
Pie plot for male and female distribution of athletes

Code:

Line Plot of Female Athletes over time

Code:

Bar-plot for Top 15 Countries and number of Gold Medals Won in the 2016 Olympics

Code:

Conclusion
It is crucial to keep in mind that EDA is an iterative process and that the steps used can change based on the dataset and the objectives of the analysis. In addition, domain knowledge and context are important factors in understanding and drawing meaningful insights from the data.